

Invariance means looking through a smaller haystack.
Invariance means looking through a smaller haystack.
Inductive biases as "invariances" in computer vision
In previous posts, I've discussed inductive biases in language models. I'd be remiss not to cover computer vision.
For inductive bias, computer vision experts look to a mathematical concept called invariance. The intuitive definition of invariance is that
you have a learner trying to map data to some set of abstractions.
Some meaningful aspects of those abstractions stay the same (are invariant) no matter how the data varies.
When the learning agent is learning patterns in the data that will help it correctly infer abstractions, it can use information about invariances to safely ignore variations in the data that don't help with that inference.
Put another way, imagine you are a robot, disembodied save for optical sensors.

You are trying to learn some mapping between images and some set of abstract concepts that characterize the images. Those concepts are defined by humans, who rely on their innate cognitive abilities and experience physically interacting with the world to make such concepts meaningful. You have none of these abilities or experiences.
All you have are giants stacks of red, green, and blue pixels and a statistical learning algorithm that will help you tie those pixels together into patterns. Some of those statistical patterns will correspond with these target concepts; some will only seem to do so, but when you try to use these patterns to infer concepts given new images, they will utterly fail you.
So the human helps you by telling you how pixels could vary across images in ways that do not affect the concepts present in the image. With this information, you can ignore that type of variation when looking for patterns.
Common invariances in computer vision.
Translation invariance
Translation invariance means the position of pixels corresponding to the concept in the overall image shouldn't matter to detecting that concept. For example, in character recognition, a written "3" could appear anywhere on an image of a written document, and it would still be the digit "3."
Similarly, if looking at an image of a room, we might suppose that the learner should learn that "couch" concept in a way that its recognition of a couch should not depend on its placement in the room.

However, if the task were to recognize musical notes from images of musical notation, recognizing a B node definitely depends on the position of the note pixels.
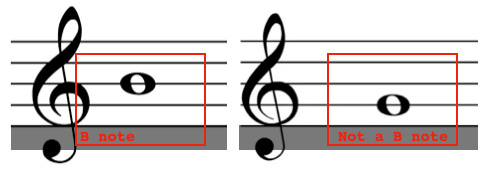
You wouldn’t want translation invariance here.
Rotation invariance
If I flipped my sofa over, snapped a picture, and texted it to you, you would know it was a couch, despite its being in an odd position.

What about written letters? If we flip a “W” should it be viewed as an “M”, or just an upside-down “W”? It would depend on the context.
Shear Invariance
If the couch were stretched in one direction, does it remain a couch? How far can it be stretched before it ceases to be a couch and becomes some art installation?

On the other hand, because of how people write, stretching of numbers and letters is expected, up to a point.

Size Invariance
A large hand-written "3" is still the digit "3." But is a giant tennis ball still a tennis ball?

Choosing the right invariance depends on the task.
There are several more invariances, such as reflection invariance, invariance to lighting conditions, etc. One thing to note is that whether or not to use a type of invariance as an inductive bias depends on the task.
We saw this in previous posts on deep language models. For example, we saw an inductive bias towards recency (such as in a recurrent neural network) performed better with languages with subject-verb-object ordering like English relative to languages with subject-object-verb ordering like Japanese.
Deep learning practitioners often miss this nuance; in my experience, people regard certain invariances as universally desirable. I suspect this is because neuroscience has interesting things to say about invariances in the visual signal processing systems that evolved in animals and humans. These results suggest some invariances get Darwinian bonus points.
Dear reader, I’d like to ask your help in growing our audience in 2021. Please support us by sharing with a friend. Happy New Year!
Invariances and deep learning
We've seen that in the case of language models, deep learning achieves inductive bias via properties of a neural network architecture. The same is true in computer vision. Namely, connective sparsity, weight-sharing, convolutions, and pooling combine to provide translation invariance. The Cohen and Shashua reference below is an excellent analysis of the inductive biases provided by these structural elements.
The trouble with relying solely on invariance for inductive bias
When you train a computer vision model on training images, the learning algorithm searches for statistical patterns in training images to help it make correct inferences on future unseen images. One might call this a "needle in a haystack" kind of problem, but it's more like
trying to find a good needle in a stack of mostly sucky needles,
where some needles seem good but actually suck,
and you can't validate goodness until you start sewing.
Invariances tell the learning agent what statistical patterns to ignore, i.e., they reduce the size of the stack. This is incredibly useful.
In subsequent posts, I'll explore ways relational inductive biases and Bayesian inductive learning help the learner sort through the remaining needles.
Go Deeper
Cohen, N., & Shashua, A. (2016). Inductive bias of deep convolutional networks through pooling geometry. arXiv preprint arXiv:1605.06743.