

Falsification by Imagination
Falsification by Imagination
How deep causal generative modeling could address algorithmic (un)fairness
What is causal generative machine learning?
Causal generative machine learning is a generative machine learning approach. Generative models can simulate synthetic data and answer prediction questions using probabilistic inference algorithms. Causal generative modeling goes a step further by explicitly modeling domain abstractions and the causal relationships between them. Moreover, they don't just simulate data; they simulate causal explanations for the data.
Deep causal generative modeling incorporates deep neural network architectures into causal generative modeling. Like common deep learning approaches, it is ideal for modeling nonlinear relationships between high-dimensional objects, like images. However, deep learning practitioners tend to avoid models that rely on domain knowledge, causality, and explanation.
Some key benefits include making causal inferences, explainability, and transferability across domains and datasets. However, these benefits come at the cost of errors that arise when your prior knowledge and causal assumptions are wrong (though causal models can be surprisingly robust to model misspecification depending on the task).
Part of the problem of algorithmic bias is hidden causal assumptions.
This sensitivity to having the wrong model is a feature, not a bug. We can falsify the assumptions of causal models using empirical evaluation on data (or at least scrutize them logically when data isn’t available). Falsification is essential to science, yet we as machine learner engineers typically focus on objectives like predictive accuracy or likelihood-based metrics (AKA goodness-of-fit).
That fixation on predictive accuracy and data-fit while ignoring the assumptions our models make about the world has hindered debate on algorithmic bias in the community. Last Summer, we argued online about algorithmic bias in the case of a generative image model called PULSE. PULSE took low-resolution images of faces and attempted to generate high-resolution images using a previously published generative model. But PULSE seemed to whitewash people of color during this generation.

We have seen with algorithmic fairness issues arise with algorithms with high predictive accuracy or generate highly accurate images. I hope you'll excuse the pun, but a model that predicts all swans are white will be highly accurate; a generative model that, when told to generate a swan, might generate convincing pictures of white swans. But new image data that contained black swans exist would falsify this model. If our models are going to make assumptions about how the world works and then affect the world after the model is deployed, the least we can do is give the world a chance to falsify those assumptions.
In other words, some aspects of algorithmic unfairness emerge as artifacts of subjective assumptions about causal workings of social, political, and other real-world phenomena that get baked into predictive algorithms during training. If those assumptions are not explicit, we cannot scrutinize and refine them. I advocate making those assumptions explicit in the form of a causal generative model. Then, not only can we will have specific modeling assumptions to scrutinize and debate, but more importantly, we can test and potentially falsify those assumptions.
We can falsify using data.
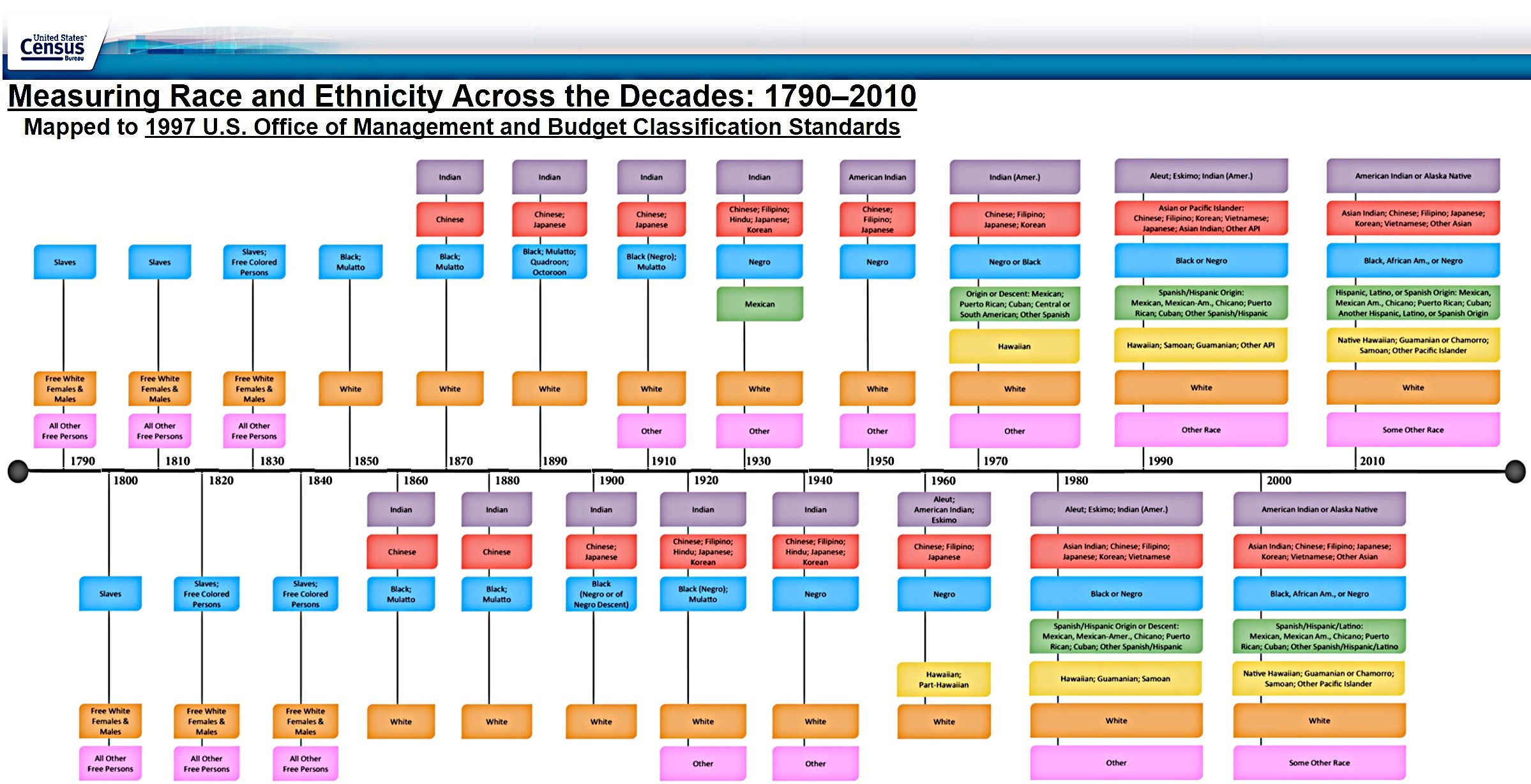
Suppose we were building a generative model of faces. We might start by building a deep causal generative model with the following causal graph structure.

In this structure;
the image node is a vector of pixels,
age, gender, and race are causes of visible physical traits that appear in the image,
and the vector Z is a latent representation that encodes independent causes we don't model explicitly.
Z is colored grey because it is unobserved. Our causal generative model will use this structure as its skeleton, and we will learn the latent representation Z using unsupervised methods during training.
A causal graph structure implies testable constraints, including (but not limited to) conditional independence constraints. For example, this structure says that the image should be independent of ethnic group given all the visible traits* .
We can test this independence assumption out. For example, we might do a sensitivity analysis during training to see how sensitive training loss or the ultimate quality of the images is to the inclusion or exclusion of the race label.
Suppose we test this out and find that this independence assumption doesn't hold. Great! We've falsified our model. Now we get to build a better one.
Know anyone who might think there’s something to these arguments? Share this post.
Iterating on a falsified model; modeling ethnic categories.
Why might that ethnic group label have unexplained paths of dependence with the outcome?
In the PULSE discussion, many commentators suggested that one could fix the whitewashing simply by curating the training data. Specifically, the idea is that someone could curate the training data such that members of various groups have a sufficient amount of representation (though the image dataset used to train the algorithm behind PULSE has a relatively diverse set of faces).
For argument's sake, let's assume engineers have the resources and incentives to do such curation (they don't). The first problem we face is categorizing the ethnicities of the faces in the image corpus to decide which ethnicities need more or less representation? The task of breaking down humans into discrete ethnic categories is not trivial. Definitions of race and ethnicity are fluid across cultural and historical context.
Further, the historical and cultural contexts that drive racial categorization include racial politics and racist ideologies that are many things, but certainly not objective.

We can make the nebulous and politically ephemeral natural of ethnic categories explicit in our model. We might reason that one of the direct causes of the visible traits of a face in an image is ancestry and that ethnicity is not equivalent to ancestry (merely a proxy of ancestry). Ancestry is a cause of an individual's ethnic classification along with the societal context.
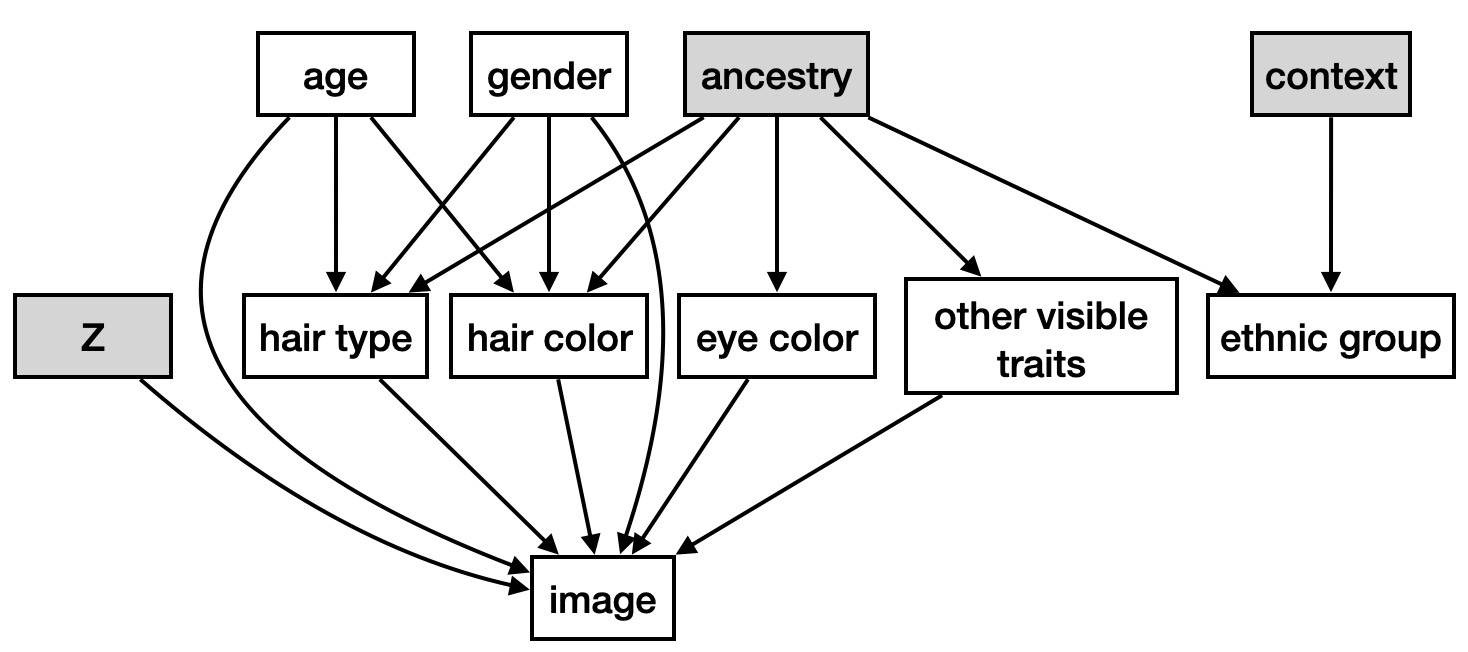
The fact that ethnic categorization is just as driven by social forces as it is by ancestry now explicit in this iteration of the model. Just as we did with Z, we can capture ancestry and context with latent representations during training.
Iterating on a falsified model; modeling how faces are assigned ethnic categories.
Suppose the hypothetical data curator uses the most recent historical "US check box" as their guide for encoding race categories.

Now, they need sort people into piles for "White", "Black, African Am, or Negro", etc.
So on which pile should the data curator place Obama's image?
The data curator might think, "we'll he's considered the first black US president, so I guess he goes into the Black, African Am, or Negro pile." Or, knowing that he’s mixed race, he might think that half-black people are historically considered black in America, as opposed to South Africa or Brazil where it’s a tad different (context).
In fact, there are several mixed-race public figures that get results from PULSE that are similar to Obama’s.


As with Obama, the data curator might want to defer to the public perception of which "pile" they belong to.
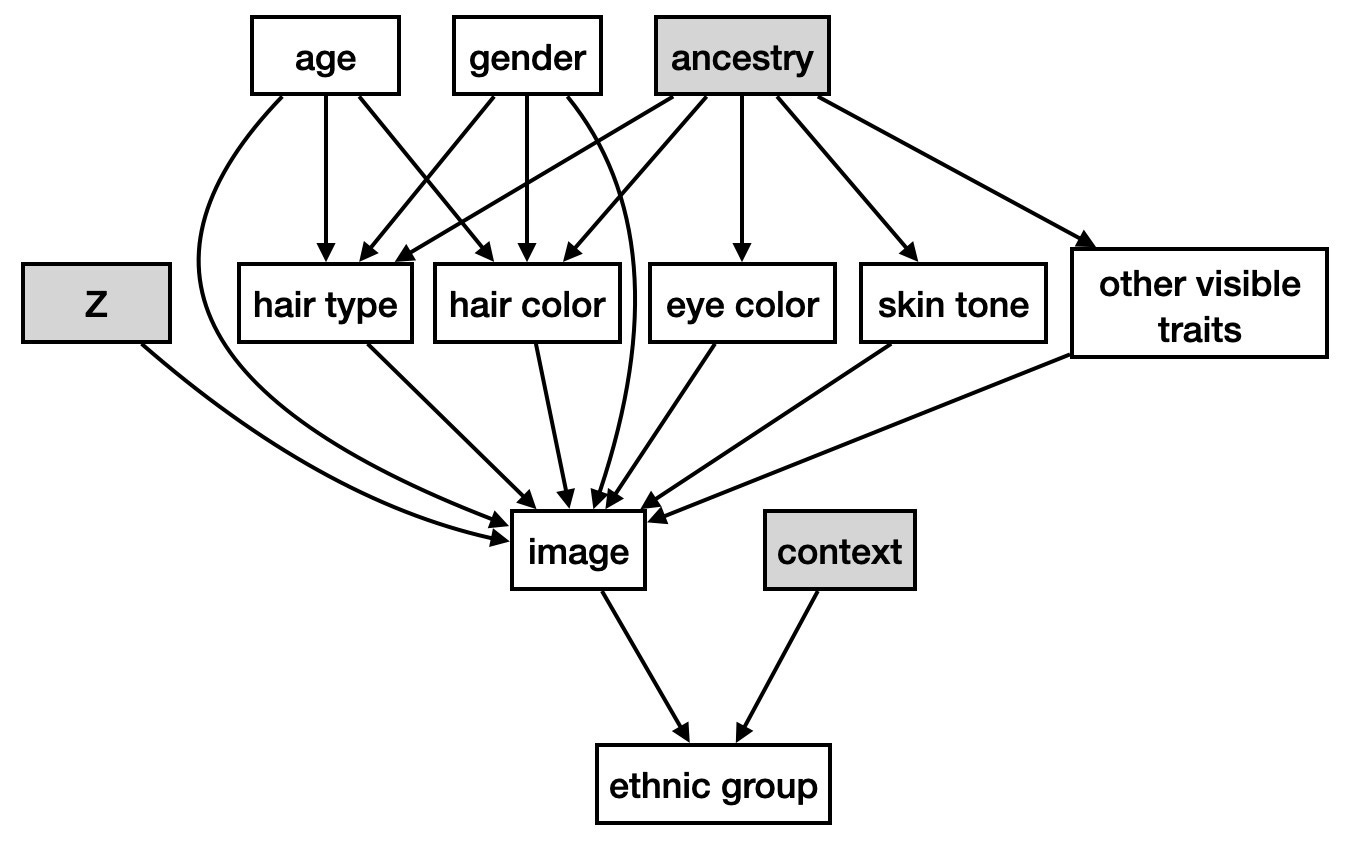
But for the anonymous faces in the dataset, the curator will make their own subjective judgments about the ethnicity of the individual in the image; judgments based on knowing nothing about the individual except what they see, and the societal/cultural context that shaped that curator's perceptions. What about black people who are often mistaked for white, like actress Rachida Jones?

The nameless subjects in the image dataset can’t speak up about their ethnic identity the way she can.
In fact, the curator doesn't even make these judgments based on observing the actual visible traits of the face; they just see a picture of those traits. In an era of makeup, filters, and touch-ups, pictures can deviate from reality.
Let's represent this in the graph.
Let's go a step further. Suppose the image corpus were ethnically biased in some way. For example, the CelebA dataset is composed of celebrities, and in the West minorities are underrepresented amongst celebrities. Let's finally adjust our model to capture the ethnic selection bias that may have gone into the image data's compilation.
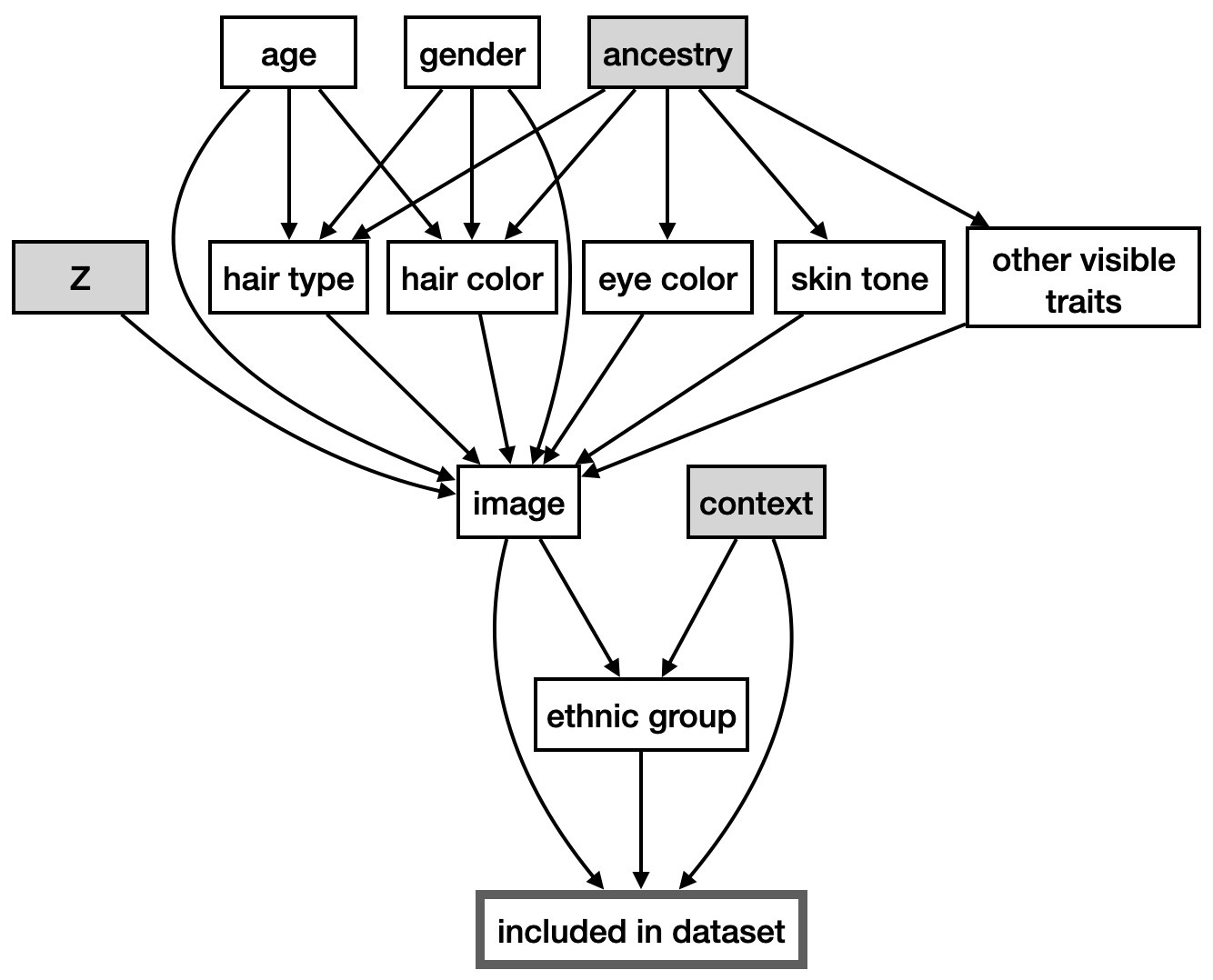
The "included in dataset" node is not latent, but rather partially observed; we only see images that were included, not those that were excluded (indicated by the grey outline).
The causal relationship between the image and ethnic group, and the selection bias, could be the source of the dependence between the ethnic group and the image that isn't explained away by visible traits.
Admittedly, it would be tough to model that context/ethnicity/included structure explicitly during training, we’d have to blackbox it, but we could do so in a way that respected the constraints imposed by these causal assumptions (e.g., conditional independence).
We can falsify using causal simulation.
So far, I have only discussed falsification and iteration based on directed graph structure. But with a deep causal generative model of faces, we can contemplate falsification by simulation.
In a deep generative model such as a GAN, we train the model to generate synthetic images as realistic as possible.
Does causal simulation align with our expectations?
In contrast, a causal generative model should be able to generate images changed by intervention. An example intervention could fix hair color to "blonde" and skin tone to "dark" and generate convincing images despite having little to no examples of dark-skinned people with blonde hair in the training data because it is a rare combination.

An intervention that changes hair color could be applied in real life. We could dye dark-skinned peoples hair blonde and evaluate if they look as if the "belong" to the samples from the intervention distribution. That’s an even better way of validating assumptions. However, not all interventions are practically or ethically feasible.
Similarly, we could do counterfactual simulation; given an image, simulate an image that is the same in all aspects except elements of the image affected by an intervention.

Of course, we already know how to train deep generative models to apply certain conditions and filters and have seen applications that use these models, such as FaceApp and deep fakes. However, a causal generative model can generate ad hoc interventions and counterfactual simulation after training without needing to optimize for such tasks during training.
Our goal is not to train a model that can perform these tasks. Rather, our goal is to validate our causal assumptions; if our causal assumptions are valid, these simulations should align with our imagination. If a model generates images that look similar to the training data, but generated interventional or counterfactual image doesn't jibe with our experiments or imagination, then we have falsified our model. Note that this is an even higher bar than falsifying based on testing conditional independence, as we did above.
This kind of model checking for counterfactual simulation is ideal for faces, because we have highly-evolved cognitive mechanisms for thinking about faces. But we are not limited to faces, Pawlowski, Castro, and Glocker (2020) show fantastic counterfactual simulations of MRI images.
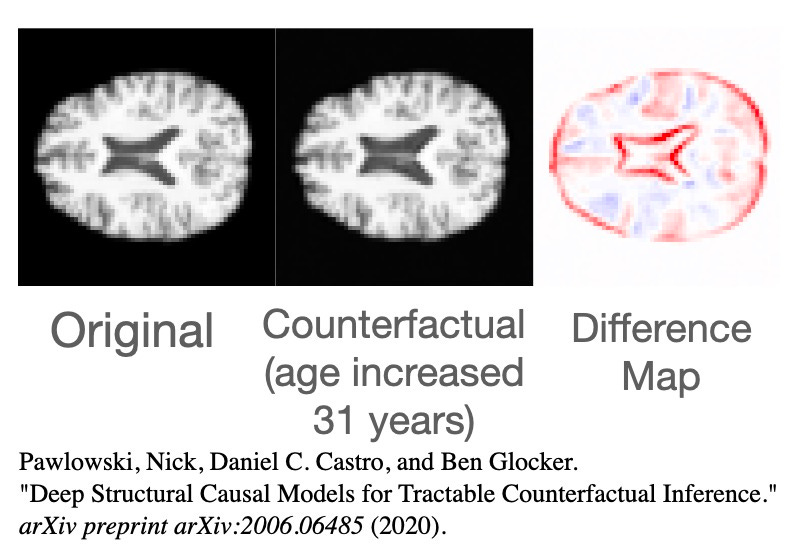
The modeler could show the original and counterfactual image to clinicians with MRI experience and ask if counterfactual simulation is consistent with their experience and intuition. If not, the causal assumptions are falsified, and the modeler looks for ways to improve the model.
Wrapping up: There are incentives not to make assumptions explicit.
We still should.
We've touched on the binning of humans into ethnicity "piles," the subjective choice of who belongs to what pile, the societal mechanisms that may have excluded some people from the image data entirely, and simulating images that change a person's race or gender. Clearly, these are thorny issues and could make that poor data curator uncomfortable.
Given that discomfort, that data curator has a strong incentive not to surface their subjective knowledge and assumptions about the data generating process in the form of an explicit model. They have an incentive to conceal them in a black box model training workflow. Then, if someone questions those assumptions, they will hear a resounding chorus that “the problem is the data set”, that “algorithms can't be racist,” that “algorithms are math and thus objective", and claims that the training data are sufficiently "diverse."
If we take a pessimistic view, some researchers are explicitly relying on the black box of machine learning to lend objectivist legitimacy to dangerous pseudoscientific ideologies. I like to think this is not generally not ill-intentioned. But one doesn’t need ill intentions to do ill. It’s been commented that machine learning is the new alchemy. It’s also the new phrenology and eugenics. Phrenologists and eugenicists, like alchemists, believed in their cause.
We need not fear making our knowledge and assumptions explicit if we can go beyond circular debates and invite others to falsify our assumptions if they have data that can do so. This will not solve all the problems of algorithmic bias. However, falsification enables us to iterate on our models in a way that looks more like science, and less like pseudoscience, especially scientific racism, or or forms of biological essentialism.
*If a directed acyclic graph is a correct representation of the causal relationships between the variables, then each variable should be conditionally independent of its non-descendants in the graph, given its parents in the graph.